

{kind=link}
Knowledge preprocessing removes errors, fills lacking data, and standardizes knowledge to assist algorithms discover precise patterns as a substitute of being confused by both noise or inconsistencies.
Any algorithm wants correctly cleaned up knowledge organized in structured codecs earlier than studying from the information. The machine studying course of requires knowledge preprocessing as its basic step to ensure fashions keep their accuracy and operational effectiveness whereas making certain dependability.
The standard of preprocessing work transforms primary knowledge collections into vital insights alongside reliable outcomes for all machine studying initiatives. This text walks you thru the important thing steps of knowledge preprocessing for machine studying, from cleansing and remodeling knowledge to real-world instruments, challenges, and tricks to increase mannequin efficiency.
Understanding Uncooked Knowledge
Uncooked knowledge is the start line for any machine studying undertaking, and the information of its nature is key.
The method of coping with uncooked knowledge could also be uneven generally. It usually comes with noise, irrelevant or deceptive entries that may skew outcomes.
Lacking values are one other downside, particularly when sensors fail or inputs are skipped. Inconsistent codecs additionally present up usually: date fields might use totally different kinds, or categorical knowledge is likely to be entered in varied methods (e.g., “Sure,” “Y,” “1”).
Recognizing and addressing these points is crucial earlier than feeding the information into any machine studying algorithm. Clear enter results in smarter output.
Knowledge Preprocessing in Knowledge Mining vs Machine Studying

Whereas each knowledge mining and machine studying depend on preprocessing to organize knowledge for evaluation, their targets and processes differ.
In knowledge mining, preprocessing focuses on making giant, unstructured datasets usable for sample discovery and summarization. This consists of cleansing, integration, and transformation, and formatting knowledge for querying, clustering, or affiliation rule mining, duties that don’t all the time require mannequin coaching.
Not like machine studying, the place preprocessing usually facilities on enhancing mannequin accuracy and decreasing overfitting, knowledge mining goals for interpretability and descriptive insights. Characteristic engineering is much less about prediction and extra about discovering significant traits.
Moreover, knowledge mining workflows might embrace discretization and binning extra incessantly, notably for categorizing steady variables. Whereas ML preprocessing might cease as soon as the coaching dataset is ready, knowledge mining might loop again into iterative exploration.
Thus, the preprocessing targets: perception extraction versus predictive efficiency, set the tone for a way the information is formed in every subject. Not like machine studying, the place preprocessing usually facilities on enhancing mannequin accuracy and decreasing overfitting, knowledge mining goals for interpretability and descriptive insights.
Characteristic engineering is much less about prediction and extra about discovering significant traits.
Moreover, knowledge mining workflows might embrace discretization and binning extra incessantly, notably for categorizing steady variables. Whereas ML preprocessing might cease as soon as the coaching dataset is ready, knowledge mining might loop again into iterative exploration.
Core Steps in Knowledge Preprocessing
1. Knowledge Cleansing
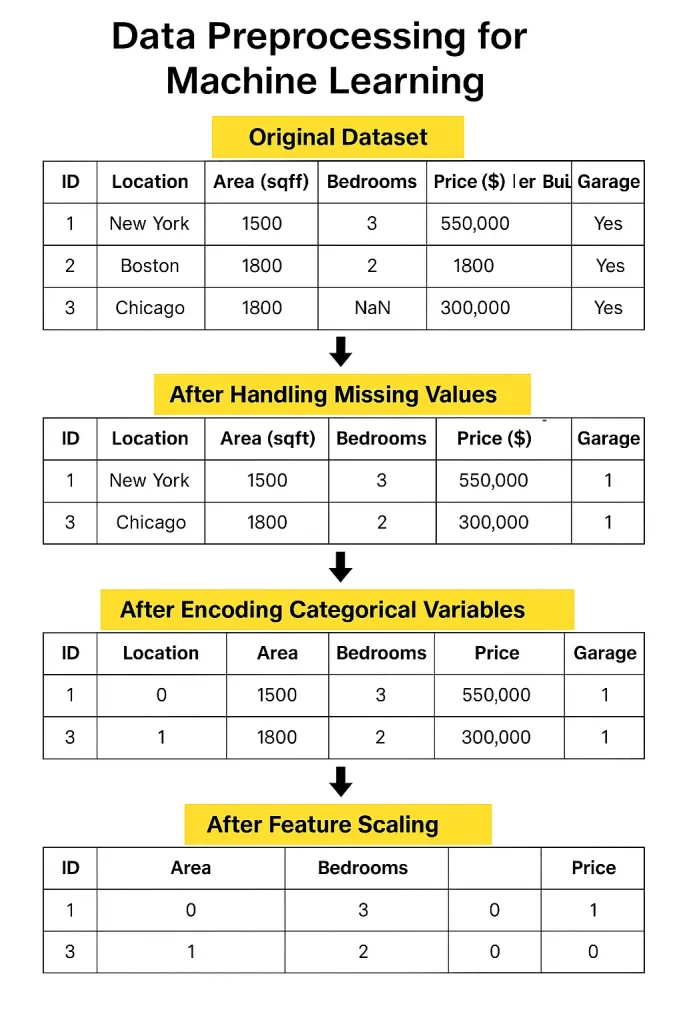
Actual-world knowledge usually comes with lacking values, blanks in your spreadsheet that must be stuffed or rigorously eliminated.
Then there are duplicates, which may unfairly weight your outcomes. And don’t overlook outliers- excessive values that may pull your mannequin within the improper course if left unchecked.
These can throw off your mannequin, so chances are you’ll have to cap, rework, or exclude them.
2. Knowledge Transformation
As soon as the information is cleaned, it’s worthwhile to format it. In case your numbers differ wildly in vary, normalization or standardization helps scale them persistently.
Categorical data- like nation names or product types- must be transformed into numbers via encoding.
And for some datasets, it helps to group related values into bins to scale back noise and spotlight patterns.
3. Knowledge Integration
Usually, your knowledge will come from totally different places- information, databases, or on-line instruments. Merging all of it may be tough, particularly if the identical piece of data seems totally different in every supply.
Schema conflicts, the place the identical column has totally different names or codecs, are frequent and want cautious decision.
4. Knowledge Discount
Huge knowledge can overwhelm fashions and enhance processing time. By deciding on solely probably the most helpful options or decreasing dimensions utilizing methods like PCA or sampling makes your mannequin sooner and sometimes extra correct.
Instruments and Libraries for Preprocessing
- Scikit-learn is superb for most simple preprocessing duties. It has built-in capabilities to fill lacking values, scale options, encode classes, and choose important options. It’s a strong, beginner-friendly library with every part it’s worthwhile to begin.
- Pandas is one other important library. It’s extremely useful for exploring and manipulating knowledge.
- TensorFlow Knowledge Validation will be useful when you’re working with large-scale initiatives. It checks for knowledge points and ensures your enter follows the right construction, one thing that’s simple to miss.
- DVC (Knowledge Model Management) is nice when your undertaking grows. It retains observe of the totally different variations of your knowledge and preprocessing steps so that you don’t lose your work or mess issues up throughout collaboration.
Frequent Challenges
One of many largest challenges at this time is managing large-scale knowledge. When you’ve got hundreds of thousands of rows from totally different sources every day, organizing and cleansing all of them turns into a severe job.
Tackling these challenges requires good instruments, strong planning, and fixed monitoring.
One other vital difficulty is automating preprocessing pipelines. In concept, it sounds nice; simply arrange a movement to scrub and put together your knowledge robotically.
However in actuality, datasets differ, and guidelines that work for one would possibly break down for one more. You continue to want a human eye to test edge instances and make judgment calls. Automation helps, however it’s not all the time plug-and-play.
Even when you begin with clear knowledge, issues change, codecs shift, sources replace, and errors sneak in. With out common checks, your once-perfect knowledge can slowly disintegrate, resulting in unreliable insights and poor mannequin efficiency.
Finest Practices
Listed here are a number of finest practices that may make an enormous distinction in your mannequin’s success. Let’s break them down and study how they play out in real-world conditions.
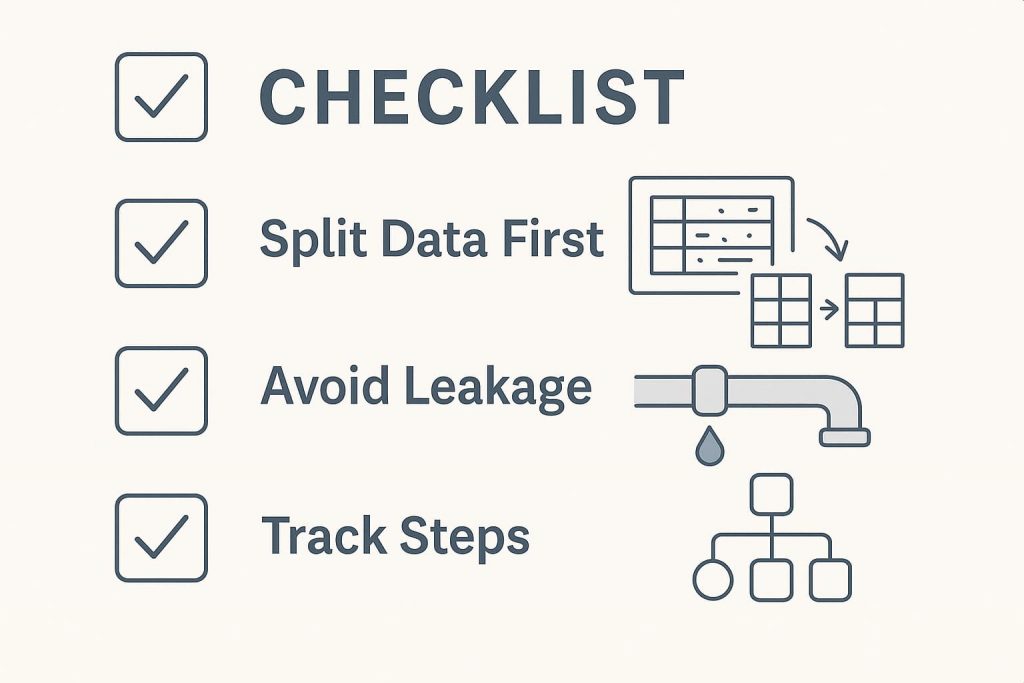
1. Begin With a Correct Knowledge Break up
A mistake many inexperienced persons make is doing all of the preprocessing on the complete dataset earlier than splitting it into coaching and check units. However this method can by accident introduce bias.
For instance, when you scale or normalize the whole dataset earlier than the cut up, data from the check set might bleed into the coaching course of, which is known as knowledge leakage.
All the time cut up your knowledge first, then apply preprocessing solely on the coaching set. Later, rework the check set utilizing the identical parameters (like imply and commonplace deviation). This retains issues honest and ensures your analysis is sincere.
2. Avoiding Knowledge Leakage
Knowledge leakage is sneaky and one of many quickest methods to break a machine studying mannequin. It occurs when the mannequin learns one thing it wouldn’t have entry to in a real-world scenario—dishonest.
Frequent causes embrace utilizing goal labels in function engineering or letting future knowledge affect present predictions. The secret’s to all the time take into consideration what data your mannequin would realistically have at prediction time and maintain it restricted to that.
3. Monitor Each Step
As you progress via your preprocessing pipeline, dealing with lacking values, encoding variables, scaling options, and maintaining observe of your actions are important not simply on your personal reminiscence but in addition for reproducibility.
Documenting each step ensures others (or future you) can retrace your path. Instruments like DVC (Knowledge Model Management) or a easy Jupyter pocket book with clear annotations could make this simpler. This type of monitoring additionally helps when your mannequin performs unexpectedly—you’ll be able to return and work out what went improper.
Actual-World Examples
To see how a lot of a distinction preprocessing makes, think about a case examine involving buyer churn prediction at a telecom firm. Initially, their uncooked dataset included lacking values, inconsistent codecs, and redundant options. The primary mannequin educated on this messy knowledge barely reached 65% accuracy.
After making use of correct preprocessing, imputing lacking values, encoding categorical variables, normalizing numerical options, and eradicating irrelevant columns, the accuracy shot as much as over 80%. The transformation wasn’t within the algorithm however within the knowledge high quality.
One other nice instance comes from healthcare. A group engaged on predicting coronary heart illness
used a public dataset that included combined knowledge sorts and lacking fields.
They utilized binning to age teams, dealt with outliers utilizing RobustScaler, and one-hot encoded a number of categorical variables. After preprocessing, the mannequin’s accuracy improved from 72% to 87%, proving that the way you put together your knowledge usually issues greater than which algorithm you select.
In brief, preprocessing is the muse of any machine studying undertaking. Comply with finest practices, maintain issues clear, and don’t underestimate its influence. When performed proper, it might take your mannequin from common to distinctive.
Incessantly Requested Questions (FAQ’s)
1. Is preprocessing totally different for deep studying?
Sure, however solely barely. Deep studying nonetheless wants clear knowledge, simply fewer handbook options.
2. How a lot preprocessing is an excessive amount of?
If it removes significant patterns or hurts mannequin accuracy, you’ve possible overdone it.
3. Can preprocessing be skipped with sufficient knowledge?
No. Extra knowledge helps, however poor-quality enter nonetheless results in poor outcomes.
3. Do all fashions want the identical preprocessing?
No. Every algorithm has totally different sensitivities. What works for one might not swimsuit one other.
4. Is normalization all the time essential?
Largely, sure. Particularly for distance-based algorithms like KNN or SVMs.
5. Are you able to automate preprocessing totally?
Not solely. Instruments assist, however human judgment continues to be wanted for context and validation.
Why observe preprocessing steps?
It ensures reproducibility and helps establish what’s enhancing or hurting efficiency.
Conclusion
Knowledge preprocessing isn’t only a preliminary step, and it’s the bedrock of fine machine studying. Clear, constant knowledge results in fashions that aren’t solely correct but in addition reliable. From eradicating duplicates to choosing the right encoding, every step issues. Skipping or mishandling preprocessing usually results in noisy outcomes or deceptive insights.
And as knowledge challenges evolve, a strong grasp of concept and instruments turns into much more worthwhile. Many hands-on studying paths at this time, like these present in complete knowledge science
In the event you’re trying to construct sturdy, real-world knowledge science abilities, together with hands-on expertise with preprocessing methods, think about exploring the Grasp Knowledge Science & Machine Studying in Python program by Nice Studying. It’s designed to bridge the hole between concept and follow, serving to you apply these ideas confidently in actual initiatives.