

{kind=link}
Multimodal giant language fashions (MLLMs) are designed to course of and generate content material throughout varied modalities, together with textual content, pictures, audio, and video. These fashions intention to grasp and combine data from completely different sources, enabling purposes akin to visible query answering, picture captioning, and multimodal dialogue methods. The event of MLLMs represents a major step towards creating AI methods that may interpret and work together with the world in a extra human-like method.
A main problem in growing efficient MLLMs lies in integrating numerous enter sorts, notably visible knowledge, into language fashions whereas sustaining excessive efficiency throughout duties. Present fashions typically wrestle with balancing sturdy language understanding and efficient visible reasoning, particularly when scaling to advanced knowledge. Additional, many fashions require giant datasets to carry out properly, making it tough to adapt to particular duties or domains. These challenges spotlight the necessity for extra environment friendly and scalable approaches to multimodal studying.
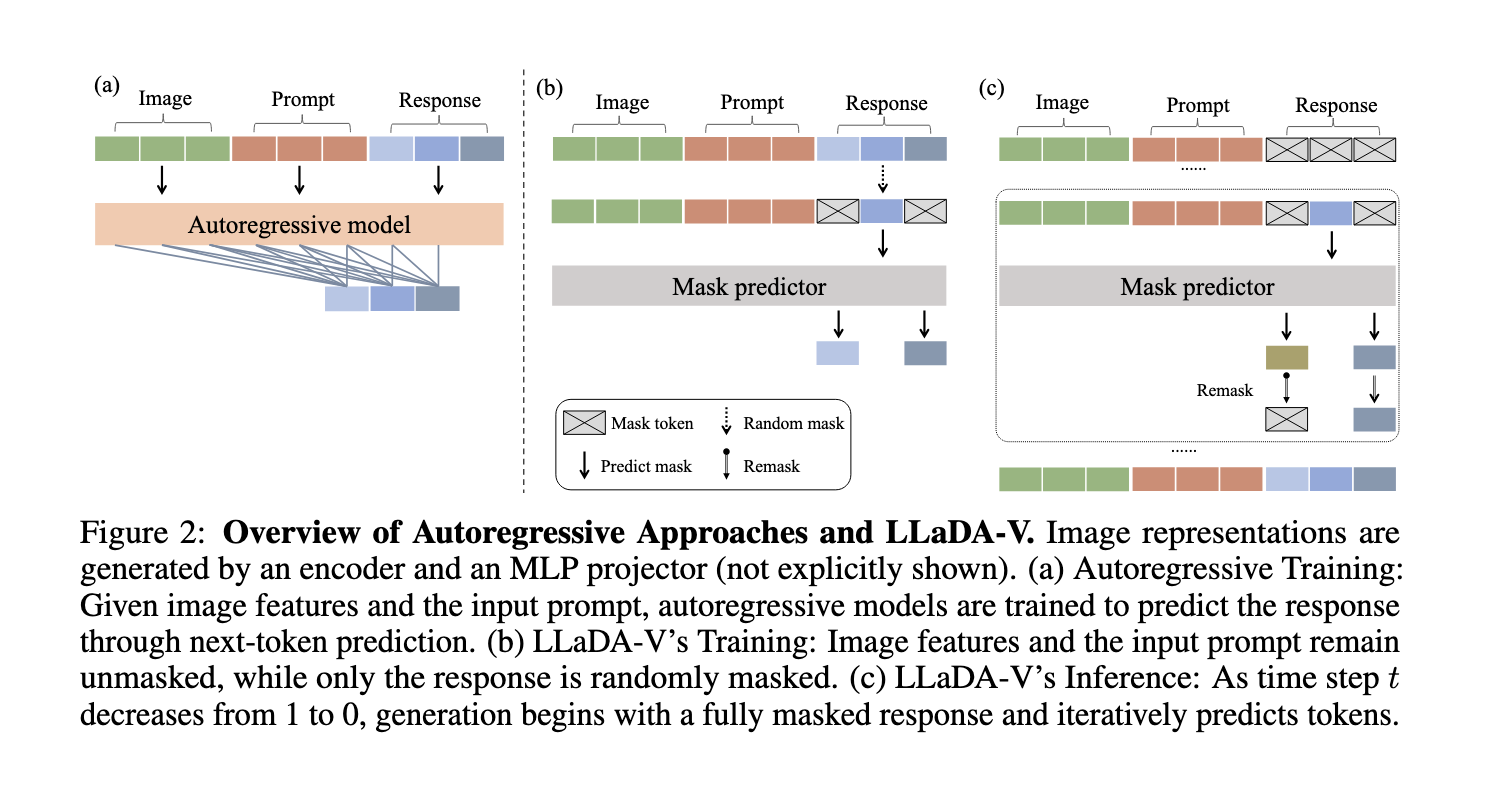
Present MLLMs predominantly make the most of autoregressive strategies, predicting one token at a time in a left-to-right method. Whereas efficient, this strategy has limitations in dealing with advanced multimodal contexts. Various strategies, akin to diffusion fashions, have been explored; nonetheless, they typically exhibit weaker language understanding attributable to their restricted architectures or insufficient coaching methods. These limitations counsel a niche the place a purely diffusion-based mannequin might supply aggressive multimodal reasoning capabilities if designed successfully.
Researchers from the Renmin College of China and Ant Group launched LLaDA-V, a purely diffusion-based masked language modeling (MLLM) mannequin that integrates visible instruction tuning with masked diffusion fashions. Constructed upon LLaDA, a big language diffusion mannequin, LLaDA-V incorporates a imaginative and prescient encoder and an MLP connector to challenge visible options into the language embedding area, enabling efficient multimodal alignment. This design represents a departure from the autoregressive paradigms dominant in present multimodal approaches, aiming to beat current limitations whereas sustaining knowledge effectivity and scalability.

LLaDA-V employs a masked diffusion course of the place textual content responses are steadily refined by way of iterative prediction of masked tokens. Not like autoregressive fashions that predict tokens sequentially, LLaDA-V generates outputs by reversing the masked diffusion course of. The mannequin is educated in three phases: the primary stage aligns imaginative and prescient and language embeddings by mapping visible options from SigLIP2 into LLaDA’s language area. The second stage fine-tunes the mannequin utilizing 10 million single-image samples and a couple of million multimodal samples from MAmmoTH-VL. The third stage focuses on reasoning, utilizing 900K QA pairs from VisualWebInstruct and a blended dataset technique. Bidirectional consideration improves context comprehension, enabling strong multimodal understanding.
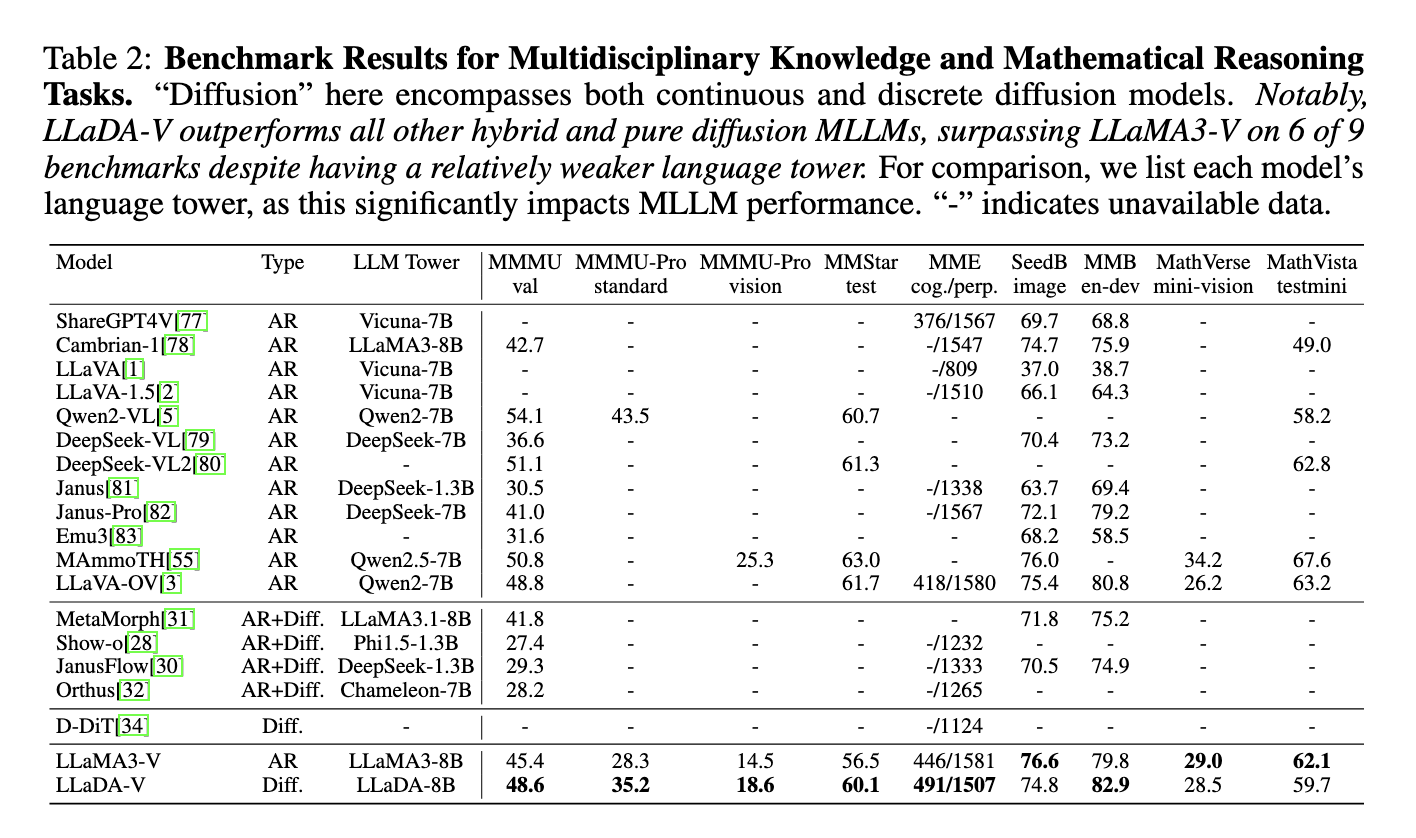
In evaluations throughout 18 multimodal duties, LLaDA-V demonstrated superior efficiency in comparison with hybrid autoregressive-diffusion and purely diffusion-based fashions. It outperformed LLaMA3-V on most multidisciplinary information and mathematical reasoning duties like MMMU, MMMU-Professional, and MMStar, attaining a rating of 60.1 on MMStar, near Qwen2-VL’s 60.7, regardless of LLaDA-V utilizing the weaker LLaDA-8B language tower. LLaDA-V additionally excelled in knowledge effectivity, outperforming LLaMA3-V on MMMU-Professional with 1M samples towards LLaMA3-V’s 9M. Though it lagged in chart and doc understanding benchmarks, akin to AI2D, and in real-world scene duties, like RealworldQA, LLaDA-V’s outcomes spotlight its promise for multimodal duties.
In abstract, LLaDA-V addresses the challenges of constructing efficient multimodal fashions by introducing a purely diffusion-based structure that mixes visible instruction tuning with masked diffusion. The strategy presents sturdy multimodal reasoning capabilities whereas sustaining knowledge effectivity. This work demonstrates the potential of diffusion fashions in multimodal AI, paving the best way for additional exploration of probabilistic approaches to advanced AI duties.
Take a look at the Paper and GitHub Web page . All credit score for this analysis goes to the researchers of this challenge. Additionally, be happy to comply with us on Twitter and don’t overlook to affix our 95k+ ML SubReddit and Subscribe to our E-newsletter.
Nikhil is an intern guide at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time researching purposes in fields like biomaterials and biomedical science. With a powerful background in Materials Science, he’s exploring new developments and creating alternatives to contribute.