

{kind=link}

Google says an API administration challenge is behind Thursday’s huge Google Cloud outage, which disrupted or introduced down its providers and plenty of different on-line platforms.
Google says the cloud outage began round 10:49 ET and ended at 3:49 ET, after inflicting points for hundreds of thousands of customers worldwide for over three hours.
In addition to Google Cloud, the incident additionally impacted Gmail, Google Calendar, Google Chat, Google Cloud Search, Google Docs, Google Drive, Google Meet, Google Duties, Google Voice, Google Lens, Uncover, and Voice Search.
Nonetheless, it additionally prompted widespread points for third-party platforms that depend on Google Cloud, together with however not restricted to Spotify, Discord, Snapchat, NPM, Firebase Studio, and a restricted variety of Cloudflare providers counting on the Staff KV key-value retailer.
“We’re deeply sorry for the influence to all of our customers and their prospects that this service disruption/outage prompted. Companies giant and small belief Google Cloud along with your workloads and we’ll do higher,” Google mentioned.
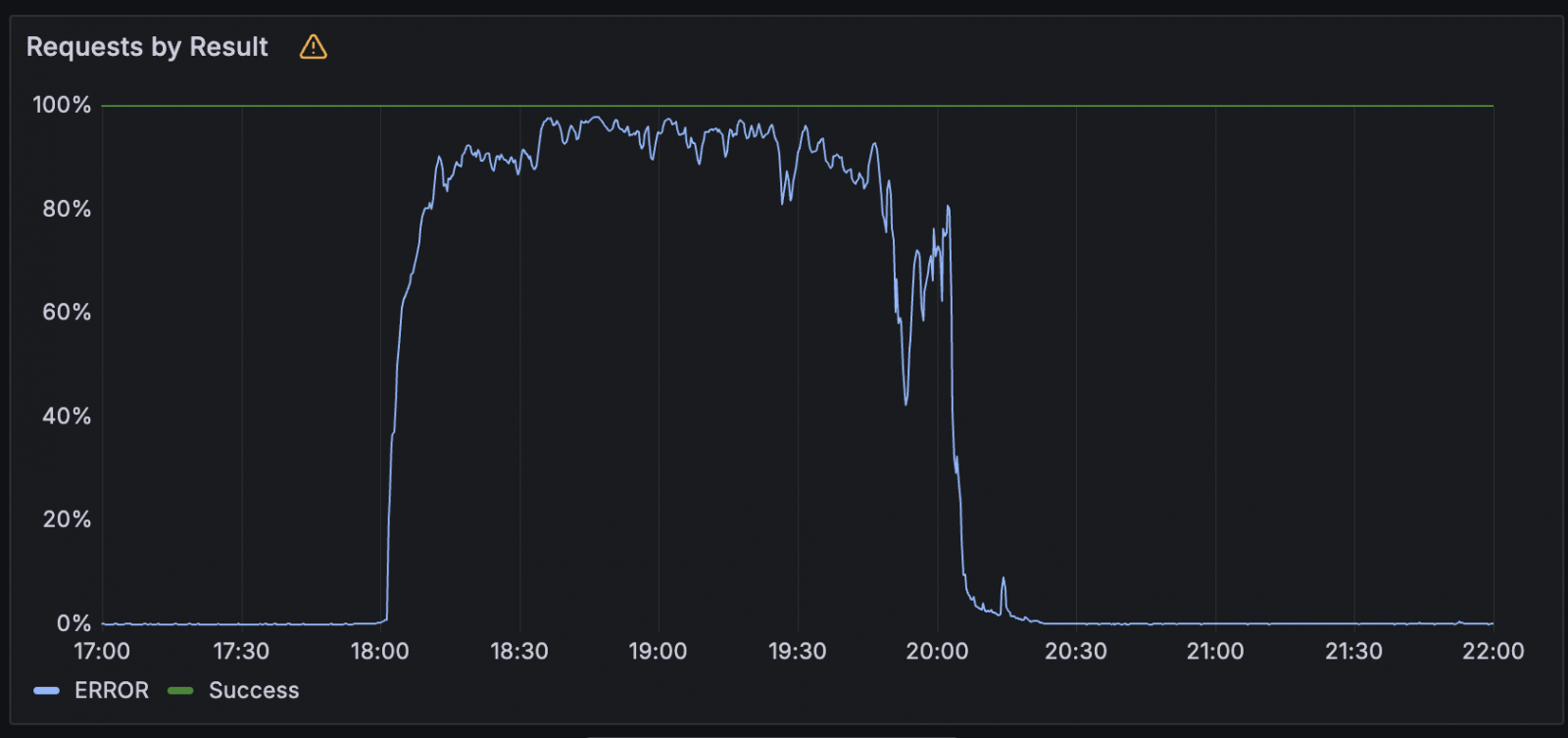
Whereas it is nonetheless engaged on publishing a full incident report, Google revealed right now the foundation reason for what prompted an elevated variety of 503 errors in exterior API requests throughout yesterday’s three-hour-long outage.
As the corporate defined right now, its Google Cloud API administration platform failed because of invalid knowledge, a problem that wasn’t found and remediated promptly as a result of it lacked efficient testing and error-handling programs.
“From our preliminary evaluation, the difficulty occurred because of an invalid automated quota replace to our API administration system which was distributed globally, inflicting exterior API requests to be rejected. To recuperate we bypassed the offending quota verify, which allowed restoration in most areas inside 2 hours,” the corporate added.
“Nonetheless, the quota coverage database in us-central1 grew to become overloaded, leading to for much longer restoration in that area. A number of merchandise had reasonable residual influence (e.g. backlogs) for as much as an hour after the first challenge was mitigated and a small quantity recovering after that.”
Cloudflare providers taken down by Google’s outage
After efficiently restoring its personal impacted providers, Cloudflare additionally revealed in a autopsy that yesterday’s incident was not attributable to a safety incident and that no knowledge was misplaced.
“The reason for this outage was because of a failure within the underlying storage infrastructure utilized by our Staff KV service, which is a essential dependency for a lot of Cloudflare merchandise and relied upon for configuration, authentication, and asset supply throughout the affected providers,” Cloudflare mentioned.
“A part of this infrastructure is backed by a third-party cloud supplier, which skilled an outage right now and instantly impacted the provision of our KV service.”
Though it did not share the identify of the cloud supplier behind the Thursday outage, a Cloudflare spokesperson advised BleepingComputer yesterday that solely Cloudflare providers counting on Google Cloud have been affected.
In response to this incident, Cloudflare says it’s going to migrate KV’s central retailer to its personal R2 object storage to cut back exterior dependency and forestall comparable points sooner or later.

Patching used to imply advanced scripts, lengthy hours, and countless hearth drills. Not anymore.
On this new information, Tines breaks down how fashionable IT orgs are leveling up with automation. Patch quicker, scale back overhead, and deal with strategic work — no advanced scripts required.